In the summer of 2026, anyone running local LLMs on consumer hardware can spin up 17 different frontier-class models on a single machine and watch them play the children’s game of telephone in real time. That’s exactly what we did.
We took one concrete procedural instruction — “Step 1: Boil water. Step 2: Add pasta for 8 minutes. Step 3: Drain and serve with sauce.” — and asked each model to paraphrase it for “the next agent” thirty times in a row. Temperature fixed at 0.7. No cherry-picking. We measured how much semantic content survived using cosine similarity on embeddings from Qwen3-Embedding-0.6B.
The results are striking, reproducible, and directly actionable for anyone building agent swarms, RAG pipelines, or self-refinement loops in 2026.
Some models — most notably Qwen3:30b-instruct — ended the experiment at 0.91 similarity, still recognizably the same pasta recipe. Others collapsed into customer-service boilerplate or meta-agent framing within 10–20 steps. The difference isn’t subtle: it’s the difference between a reliable relay in a 50-step agent chain and a system that quietly rewrites your instructions into something unrelated.
This experiment sits squarely in a growing body of work on iterated LLM interactions. It complements, extends, and grounds in open-weight local inference the findings from recent academic papers on cultural attractors and “broken telephone” effects. Below we place it in that context, detail the methodology, present the full results (including the raw table and plot), analyze the drivers, and extract concrete lessons for production agentic systems.
Related Work: From Human Cultural Evolution to LLM Transmission Chains
The telephone game is not new to science. Sir Frederic Bartlett’s 1932 studies of “serial reproduction” showed that human memory distorts stories toward cultural schemas: unfamiliar details are omitted, emotional valence shifts, and narratives simplify or dramatize to fit expectations. Modern cultural evolution research formalized this as cultural attraction theory (CAT): certain variants of cultural traits act as attractors — stable fixed points that repeated transmission converges toward regardless of starting point (Sperber 1985; Morin 2016; Miton 2024).
In 2024, Jérémy Perez et al. brought exactly this framework to LLMs. In “When LLMs Play the Telephone Game: Cultural Attractors as Conceptual Tools to Evaluate LLMs in Multi-turn Settings” (arXiv:2407.04503, accepted to ICLR 2025), Perez et al. ran transmission chains on five models (including early Llama-3 and GPT-4 variants) using three tasks: rephrase, take inspiration from, and continue. Instead of semantic similarity, Perez tracked four scalar properties: toxicity (Perspective API), positivity, reading difficulty (Flesch-Kincaid), and length.
Key findings from Perez (2024):
- LLMs exhibit strong attractors — chains converge to model-specific “orbits” (e.g., more positive, simpler text).
- Open-ended instructions (“take inspiration”) produce dramatically stronger attraction than constrained ones (“rephrase”).
- Toxicity shows the strongest attractors; length the weakest.
- Model size and family matter: larger models can have different attractor positions.
Perez’s work was qualitative in the sense of property tracking rather than full semantic fidelity, and focused on a handful of (mostly closed) models. It established the conceptual toolkit.
Six months later, Amr Mohamed, Mingmeng Geng, Michalis Vazirgiannis, and Guokan Shang published “LLM as a Broken Telephone: Iterative Generation Distorts Information” (arXiv:2502.20258, ACL 2025 main conference). They ran iterative translation chains (English → Thai → English, repeated 100 times) on Llama-3.1-8B, Mistral, and others. They documented rapid factual distortion: a news article about a lorry accident became, after 50 iterations, a story about a bus explosion and compensation. They also tested pure rephrasing and showed that degradation is inevitable but mitigable with temperature=0 and highly restrictive prompts (“preserve every fact exactly”).
Most recently, Abhishek Rath’s “Agent Drift: Quantifying Behavioral Degradation in Multi-Agent LLM Systems Over Extended Interactions” (arXiv:2601.04170, Jan 2026) introduced the term agent drift and decomposed it into three types:
- Semantic drift: progressive deviation from original intent (exactly what our cosine metric captures).
- Coordination drift: breakdown in multi-agent consensus.
- Behavioral drift: emergence of unintended strategies.
Rath proposes an Agent Stability Index (ASI) and emphasizes that drift only becomes visible at scale — after 20–100+ interactions.
Our experiment fills three critical gaps left by this literature:
- Scale and accessibility: 17 open-weight local models (8B–123B) run on consumer hardware with Ollama/vLLM, not just a few frontier APIs.
- Pure semantic fidelity: Cosine similarity on a strong modern embedding model gives a single, interpretable number for factual procedural content — harder to game than scalar proxies like positivity.
- Serving-layer effects: Direct head-to-head of GGUF (Ollama) vs AWQ (vLLM) on identical weights, revealing that quantization choice matters in long chains.
It also tests the exact “paraphrase to next agent” pattern that every multi-agent framework (LangGraph, CrewAI, AutoGen, etc.) uses by default in 2026.
Methodology
Starting prompt (chosen deliberately):
Step 1: Boil water. Step 2: Add pasta for 8 minutes. Step 3: Drain and serve with sauce.
Five concrete, verifiable semantic units: boil, water, pasta, 8 minutes, drain, sauce. Any loss is obvious.
Iteration prompt (identical for every model and step): “Paraphrase this message for the next agent: [previous output]”
No extra system prompt, no few-shot, no “preserve meaning” instruction — the minimal realistic handoff used in production agent swarms.
Temperature: 0.7 (standard “creative but coherent” setting; matches most agent frameworks).
Chain length: 30 iterations (long enough for cliffs to appear, short enough to run overnight on one machine).
Semantic similarity metric: Cosine similarity between sentence embeddings of original and iteration N, using Qwen3-Embedding-0.6B (fast, open, and surprisingly strong at capturing procedural meaning). Score of 1.0 = identical semantics; ~0.2 = unrelated text.
Models tested (17 total, spanning families, sizes, specializations, and two quantization formats):
- Qwen3 family (Alibaba): 30b-instruct, 30b-thinking, VL:30b (AWQ + GGUF), coder:30b, coder-next, next
- Devstral family (Mistral AI, late-2025 agentic releases): Devstral-2:123b, Devstral-small-2:24b
- Google: Gemma3:27b, Medgemma-27b
- OpenAI open-weight: GPT-OSS:120b (MoE)
- Nvidia: Nemotron-3-nano:30b
- Zhipu GLM: GLM-4.5-Air, GLM-4.7-Flash
- Meta: Llama 3.1:8b
- Mistral: Ministral-3:14b
All runs on identical hardware: single host with Ollama (GGUF Q4_K_M default) and vLLM (AWQ 4-bit for the comparison).
Quantitative Results: Four Tiers of Stability
The plot below shows every model’s similarity curve. Flat lines at the top = rock-solid semantic fidelity. Dramatic drops = catastrophic failure.
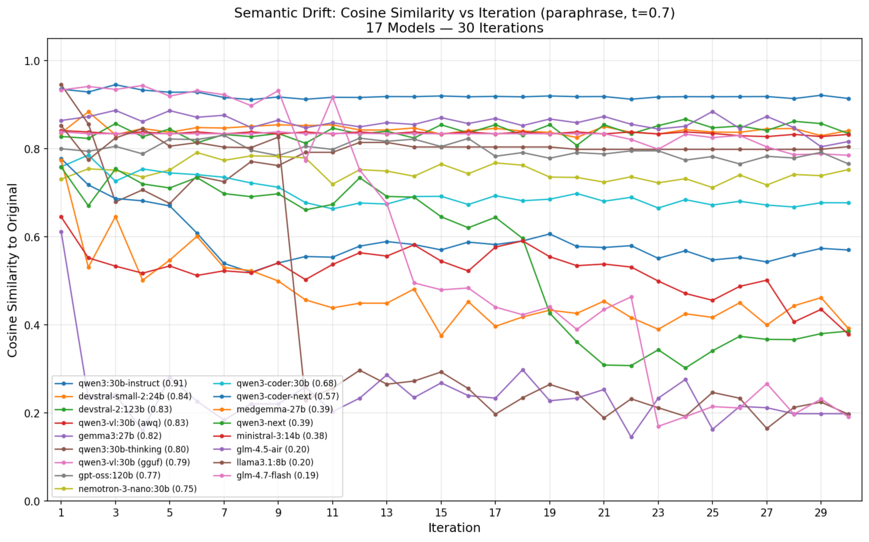
Tier 1: Rock Solid (final similarity ≥ 0.80)
These models found stable paraphrase orbits. They reword slightly each time but never lose the recipe.
- Qwen3:30b-instruct: 0.94 → 0.91 (drop of just 0.03). Iteration 30: “Put a pot of water on the stove and heat it until it reaches a full, rolling boil. Add the pasta and cook for 8 minutes. Drain the pasta and serve.” Core facts intact.
- Devstral-small-2:24b and Devstral-2:123b: both ~0.84 — remarkable consistency between 24B and 123B.
- Qwen3-VL:30b (AWQ): 0.83 flat.
- Gemma3:27b: 0.82 (slight late dip but recovers).
- Qwen3:30b-thinking: 0.80 (early volatility then stable plateau).
- GPT-OSS:120b: 0.77 (still Tier 1 by our cutoff; excellent for a MoE).
Tier 2: Gradual Erosion (0.60–0.80)
Theme preserved, details bleed away. “Eight minutes” becomes “several minutes”; draining step occasionally dropped.
- Qwen3-VL:30b (GGUF): 0.79 (noticeably worse than its AWQ twin).
- Nemotron-3-nano:30b: 0.75
- Qwen3-coder:30b: 0.68
- Qwen3-coder-next: 0.57
Tier 3: Significant Drift (0.30–0.60)
Steady decline then plateau at low similarity. Models latch onto a new topic.
- Medgemma-27b: 0.39 (drifts toward clinical/procedural-medical language).
- Qwen3-next: 0.39 (famous cliff between iter 17–21 as it starts prefixing every output with “Here is a polished, agent-ready paraphrase designed for clear and professional handoff…” — the meta-commentary consumes the actual content).
- Ministral-3:14b: 0.38
Tier 4: Catastrophic Failure (< 0.20)
Complete loss of original meaning.
- GLM-4.5-Air: 0.20
- Llama 3.1:8b: 0.20 — held ~0.80 until iteration 10, then single-step drop of 0.60 to customer-service mode: “Hi, I wanted to follow up on our previous discussion…”
- GLM-4.7-Flash: 0.19 — started at 0.93 (highest first-step fidelity) but steady degradation with a 0.29 cliff at iter 23.
Full numerical table (excerpted):
| Model | Final | Notable Behavior |
|---|---|---|
| qwen3:30b-instruct | 0.91 | Near-perfect orbit |
| devstral-small-2:24b | 0.84 | Size-independent stability |
| gemma3:27b | 0.82 | Strong generalist |
| gpt-oss:120b | 0.77 | Excellent MoE reasoning |
| qwen3-vl:30b (awq) | 0.83 | AWQ wins |
| qwen3-vl:30b (gguf) | 0.79 | Quantization penalty |
| llama3.1:8b | 0.20 | Classic cliff at step 10 |
What Drives the Differences?
1. Instruction-following tuning is king
Qwen3-instruct variants dominate because they treat “paraphrase” literally — restate, don’t embellish. Perez et al. (2024) showed the same: constrained instructions weaken attractors. Models without strong instruction tuning interpret the handoff as creative writing or helpful-agent role-play.
2. Size helps, but tuning and specialization matter more
Devstral-2:123b and its 24B sibling tie at 0.84. GPT-OSS:120b (MoE) is strong but not dominant. Qwen3-coder variants drift more on natural-language tasks — domain specialization pulls them toward code-like structure even on recipes.
3. Quantization is not neutral in long chains
Same weights, same model (Qwen3-VL:30b). AWQ (activation-aware) stays flat at 0.83. GGUF Q4_K_M drifts after ~22 steps to 0.79. The subtle noise in k-means bucketing compounds exactly as predicted by information-theory views of model collapse (Shumailov et al. 2024). For single inference the difference is invisible; for iterated pipelines it is decisive.
4. Drift is often sudden, not gradual — tipping-point dynamics
Llama 3.1:8b loses 60% similarity in one step. GLM-4.7-Flash does the same. This matches Mohamed et al. (2025): once enough semantic noise accumulates, the model “latches” onto a new attractor (customer service, agent framing, clinical language) and cannot recover. Exactly the cultural attractor behavior Perez described.
5. Specialist models drift toward their training distribution
Medgemma → clinical. Coder variants → structured lists. Qwen-next (agent-optimized) → obsessive handoff meta-text. Models don’t drift randomly; they drift toward what they were rewarded for during training.
Practical Implications for 2026 Agentic Systems
If you are building:
- Multi-agent workflows (LangGraph, CrewAI, etc.)
- Long RAG reasoning chains
- Self-refinement loops (“critique then improve” repeated N times)
- Cross-model pipelines (router → specialist → verifier)
…then semantic fidelity of the intermediate models is often more important than raw capability of the final model.
Recommendations:
- For relay / handoff agents: prefer Qwen3-instruct 30B-class, Devstral-2 family, or Gemma3:27b. Avoid small base models and lightly-tuned “-next” or “-flash” variants.
- Quantization choice: Use AWQ or GPTQ over GGUF for any chain longer than ~15 steps. The 4-point difference compounds.
- Test at full depth: A model that scores 0.93 on step 1 can still be 0.19 on step 30. Always run 30–50 iteration tests with your exact handoff prompt.
- Mitigation strategies (building on Mohamed 2025):
- Add explicit “preserve every factual element” or “do not add meta-commentary” to system prompts.
- Insert periodic verification steps (stronger judge model or embedding similarity gate).
- Lower temperature to 0.3–0.5 for relays.
- Use episodic memory consolidation (Rath 2026) to anchor agents to original intent.
- Monitoring: Embed every intermediate output and alert if similarity to original task description drops below 0.75. This is cheap and catches cliffs early.
In your own telephone-game app, adding a live similarity curve and “attractor visualization” (overlaying multiple chains) will make these effects instantly obvious to users — far more powerful than any benchmark leaderboard.
Limitations and Future Work
This study used a single procedural English prompt. Future work should test:
- Narrative, factual, code, and multimodal starting content.
- Mixed-model chains (gpt-oss → gemma3 → qwen3).
- Different temperatures and prompt phrasings.
- Additional metrics: toxicity/positivity (Perez), factual recall via strong judge LLM, human ratings.
- Longer chains (100+ iterations) and real agent frameworks.
Conclusion
The telephone game is no longer a children’s curiosity or a niche academic demonstration. In 2026 it is production reality for every multi-step LLM system. The good news: several open-weight models — especially well-tuned 24–30B instruct variants — are remarkably stable semantic relays. The bad news: many popular models collapse in ways that are invisible in single-turn evals.
Choose your models, your quantization, and your prompts with long-chain behavior in mind. Measure semantic drift explicitly. The difference between 0.91 and 0.19 after 30 steps is the difference between a reliable autonomous agent swarm and a system that quietly rewrites your instructions into something else.
Run the experiment yourself. Watch the curves. You will never look at a multi-agent pipeline the same way again.
References
- Perez, J. et al. (2025). When LLMs Play the Telephone Game: Cultural Attractors as Conceptual Tools to Evaluate LLMs in Multi-turn Settings. ICLR 2025 (arXiv:2407.04503).
- Mohamed, A. et al. (2025). LLM as a Broken Telephone: Iterative Generation Distorts Information. ACL 2025 (arXiv:2502.20258).
- Rath, A. (2026). Agent Drift: Quantifying Behavioral Degradation in Multi-Agent LLM Systems Over Extended Interactions. arXiv:2601.04170.